Week 2#
Lecturer: Barsha Mitra, BITS Pilani, Hyderabad Campus
Date: 31/Jul/2021
NOTE THAT THIS PAGE HAS DIAGRAMS THAT ARE BEST VISIBLE IN LIGHT MODE
Topics Covered#
Module 1
- Multicomputer parallel systems
- NUMA (Non Uniform Memory Access) Model
- Wraparound mesh interconnection in an MPS
- Hypercube interconnection in an MPS
- Distributed/Parallel Computing Jargon
- Parallelism/Speedup
- Parallel/Distributed Program Concurrency
- Distributed Communication Models
- RPC (Remote Procedure Call)
- Publish/Subscribe
Module 2
- Preliminary understandings
- Notations
- Space time diagram
- What are these letters?
- Causal precedence/dependency or happens before relation
- Concurrent events
Module 1#
Multicomputer parallel systems#
- Processors do not have direct access to shared mem.
- Usually do not have a common clock.
- Processors are in close proximity. (THIS IS DIFFERENT FROM A DS)
- Very tightly coupled. (THIS IS DIFFERENT FROM A DS)
- Connected by an interconnection network.
- Communicate via Message passing APIs/common address space. (THIS IS DIFFERENT FROM A DS as DS can only use MP APIs).
- Typically this is used for high performance computing use cases.
NUMA (Non Uniform Memory Access) Model#
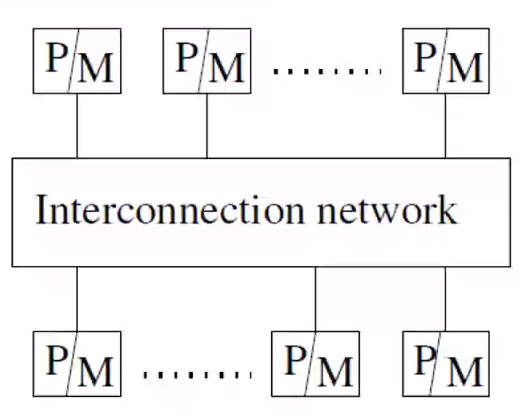
- Above you can see that the individual mem components are not clubbed together like the UMA Model (See here Week1DC#UMA Uniform Memory Access Model).
- The processor can still access the mem components but have a different access latency
- non-uniform memory access - Different processor can have different access latency
- Multicomputer system having a common address space.
- Latency to access various shared memory location from the different processors varies.
Wraparound mesh interconnection in an MPS#
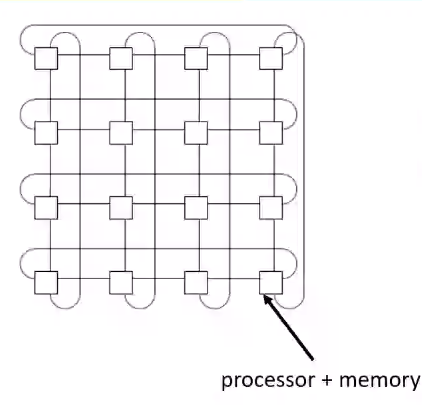
- The above diagram shows a 2d wraparound mesh
- The above diagram corresponds to a \(4x4\) mesh containing 16 nodes.
- Each node is connected to each and every node around it. The leaf nodes wrap around to the opposite leaf node of their respective row or column, hence the name Wrap Around Configuration.
- If any of the nodes go down, the wrap around connection helps in maintaining the connection.
- The connection can be bidirectional through a bus or any interconnection logic for that matter.
Hypercube interconnection in an MPS#
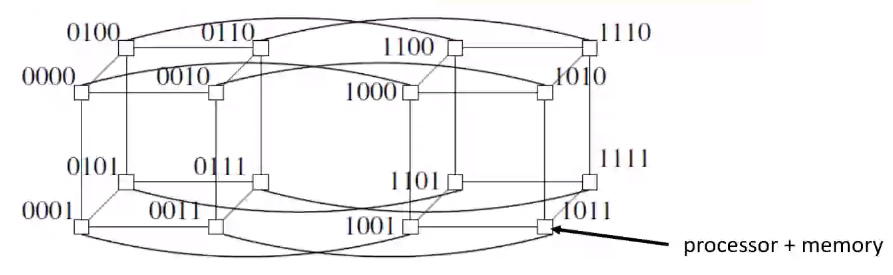
- A k dimensional hypercube has \(2^k\) processor and mem units (nodes)
- Each node has at most \(k\) connections
- Each dimension is associated with a bit position in the label
- Labels of two adjacent nodes differ in the \(k^{th}\) bit position for the dimension k
- From node \(0000\) we can see that each direction differs by a single bit. bottom is \(0001\), right is \(0010\) and the adjacent one is \(0100\)
- We can by applying the above rules get to know the label for the other adjacent nodes
- The shortest path between any two processors is called Hamming distance
- consider two bit labels \(0110\) and \(1001\), the hamming distance would be 4 since all \(4\) bits differ.
- consider two bit labels \(0111\) and \(0110\), the hamming distance would be 1 since only \(1\) bit differs.
- The above calculations can be used to connect the nodes according to the label
- In the case of such an interconnection the \(hamming\ distance <= k\)
- Even if some of the nodes go down, there will be another path present to keep the connection alive. This provides fault tolerance and congestion control mechanism
- Routing of messages happen hop by hop
Distributed/Parallel Computing Jargon#
Parallelism/Speedup#
- \(T(1)\) = Time taken on a single processor
-
\(T(n)\) = Time taken with n processors
-
Measure of the relative speedup of a specific program on a given machine
- This depends on:
- Number of processors
- Mapping of the code to the processors
Parallel/Distributed Program Concurrency#
- \(number\ of\ local\ operations\) -> Non communication and non shared memory access operations
- \(total\ number\ of\ operations\) -> All operations including communication or shared memory access
Distributed Communication Models#
RPC (Remote Procedure Call)#
This topic is covered in a pre reading session here: PreRecordedModule12#RPC Remote Procedure Call
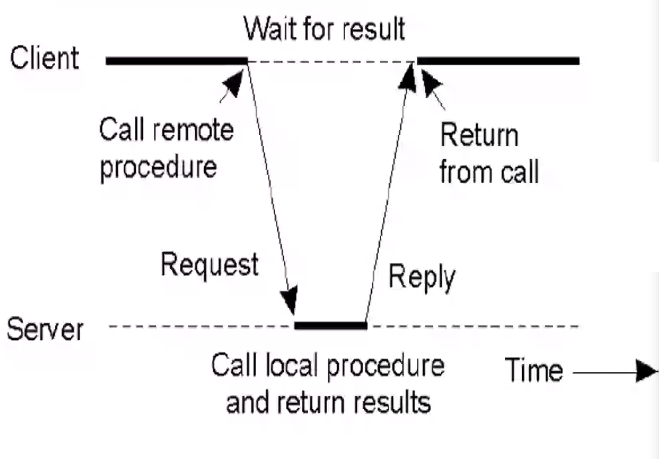
- The client procedure calls a client stub to pass params
- The client marshals the params (makes a common representation of the params), builds the message, and calls the local OS
- The local OS sends the message to the remote OS
- The server's remote OS gives the message to a server stub
- The server stub de-marshals the params(Converts common form to server OS specific form) and calls the desired server routine
- The server computes the result and hands it to the server stub
- The server stub marshals the result into a message and calls the local OS
- The server OS sends the message to the client OS
- The client OS receives the message and sends it to the client stub
- The client stub demarshals the result, and execution returns to the client
Publish/Subscribe#
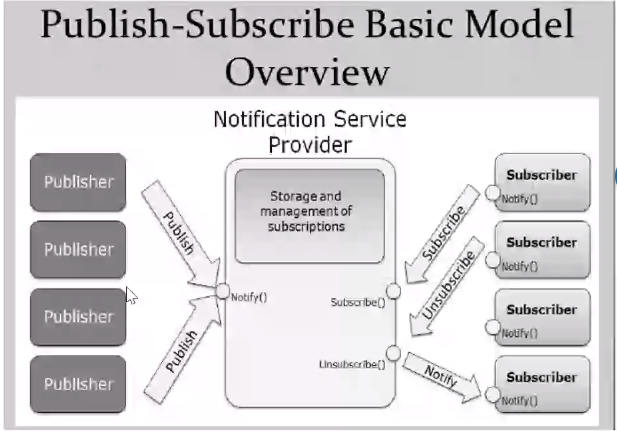
- We have two entites mainly:
- Publishers: Those who create information and publish them to a service (Through a Notify() call)
- Subscriber: Those who consume the content published by publishers it had subscribed to.
- The Subscriber gets data asynchronous though a notification, and they can continue their tasks until they receive notifications.
- The subscriber has an option to unsubscribe as well
Module 2#
Preliminary understanding#
- DS consists of a set of processors.
- There is an intercommunication network.
- Delay in communication is finite but is not predictable.
- Processors do not share a common global memory.
- Uses asynch message passing.
- No common physical global clock.
- Possibility of messages being delivered out of order.
- Messages may be lost, garbled or duplicated due to timeouts and retransmissions.
- There is always a possibility of communication and processor failure.
Notations#
- \(C_{ij}\) : Channel from process \(p_i\) to process \(p_j\)
- \(m_{ij}\) : message sent by \(p_i\) to \(p_j\)
-
Global state \(GS\) of a distributed computation consists of:
- States of the processes: Local memory state
- States of the communication channels: set of messages in transit
Global state is explained in detail here PreRecordedModule12#Global state of a DS
- Occurrences of events \(e\)
- Causes changes in respective processes states
- Causes changes in channels states
- Causes transition in global system state
Space time diagram#
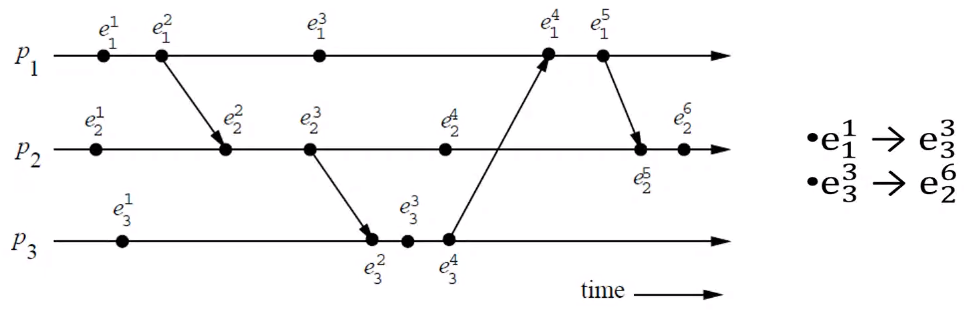
What are these letters?#
- \(p_i\) denotes the processes in the space axis
- \(e_i^j\) denotes the \(j^{th}\) event in process \(p_i\)
- Events that do not have arrows are
- The arrows denote the direction of the message sent.
- \(e_1^2\) is a message sending event
- \(e_3^2\) is a message receive event
Causal precedence/dependency or happens before relation#
- Relation '\(\rightarrow\)' denotes flow of information in a distributed computation
- \(e_i \rightarrow e_j\) implies that all the information at \(e_i\) is accessible at \(e_j\)
- In the above example we can see that \(e_1^1\) has a complete path to \(e_3^3\) hence we can be certain that \(e_1^1 \rightarrow e_3^3\)
Concurrent events#
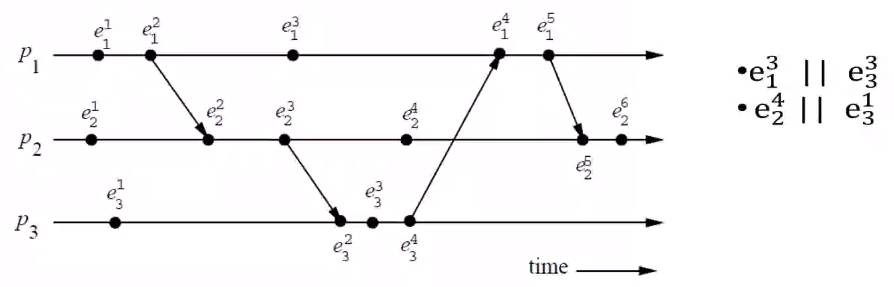
- For any two events \(e_i\) and \(e_j\), if there are no paths that connect directly to each other then these two are concurrent and is denoted as \(e_i\ ||\ e_j\)
- Concurrency is a non transitive relation meaning if \(e_i\ ||\ e_j\) and \(e_j\ ||\ e_k\) we cannot say that \(e_i\ ||\ e_k\)
- In the above example \(e_2^4\) and \(e_3^1\) are not connected at all hence, we can say that \(e_2^4\ ||\ e_3^1\)