Module 7#
Unsupervised Learning#
In this kind of learning we deal with unlabelled data.
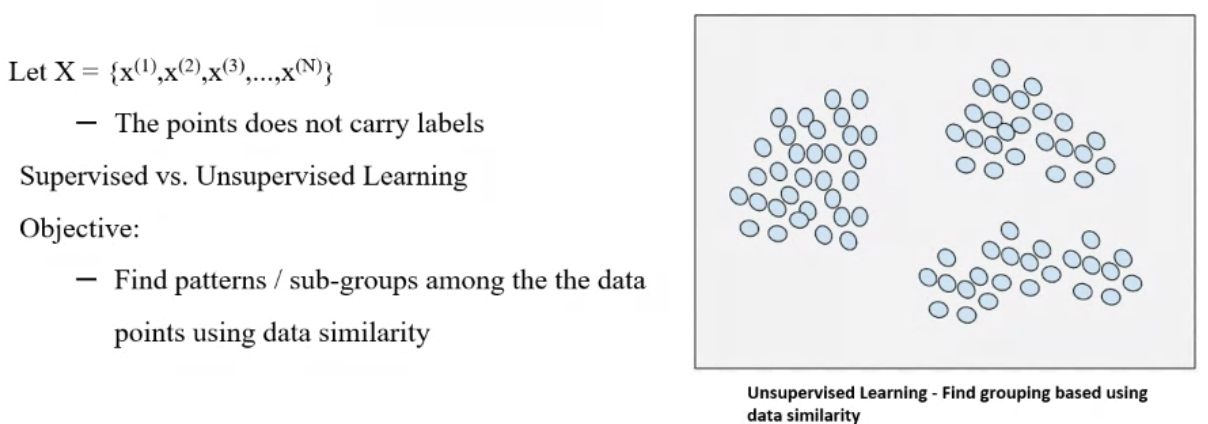
Unspuervised Learning Forms:
1. Clustering
2. Association RA
3. Outlier Analysis
4. Dimensionality Reduction (PCA)
Clustering#
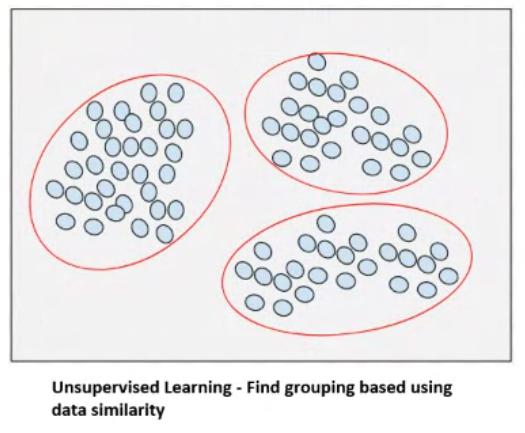
Clustering aims to find grouping in data
- Given a \(X\) find \(K\) clusters using data similarity
- Minimize intra cluster distance and maximize inter cluster distance. We use proximity measures to know the distances.
- The quality of a clustering result depends on both the similarity measure used by the method and its implementation
Clustering is used in applications where dcouments need to categorized
It is also used in recommendation system
Types#
- Partitional Clustering: K Means
- Hierarchical
- Density
- Distribution based: Guassian Mixture
Proximity Measure For Binary Attributes#

Dissimilarity Between Binary Variables#

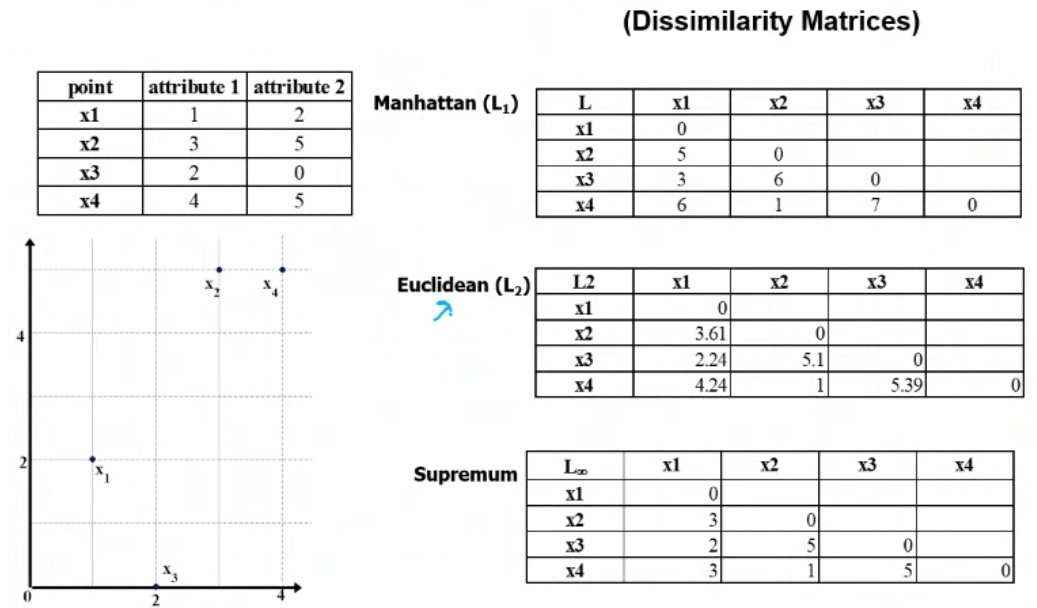
- Manhattan: Sum of Absolute differences
- Euclidean distance: Straight line distance between two data points
- Supremum: Maximum absolute difference sum
We need to normalize data to avoid some attributes do not contribute more than others
Distance for mixed attribute types Gower Distance#

Example#
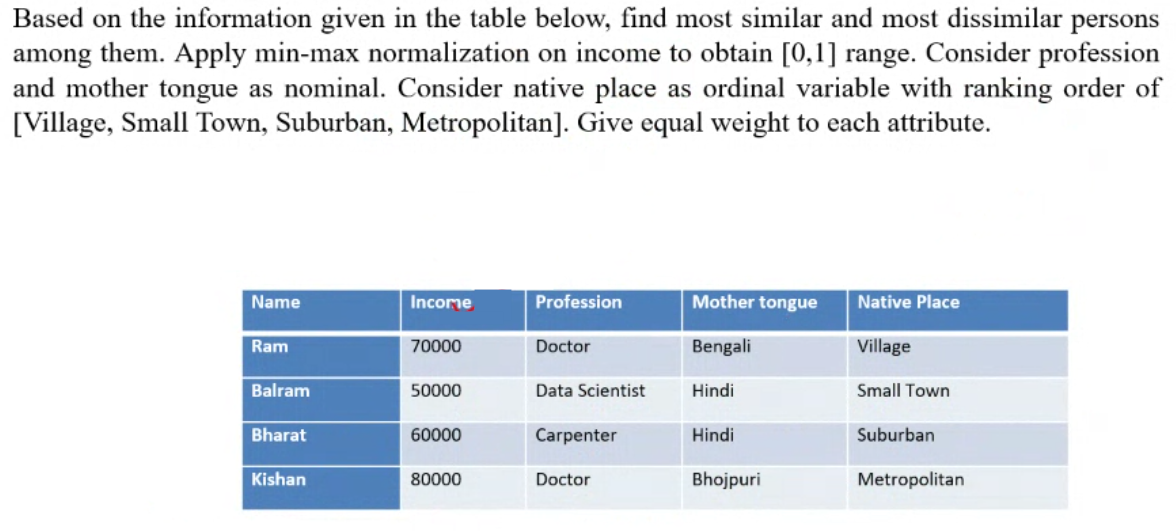
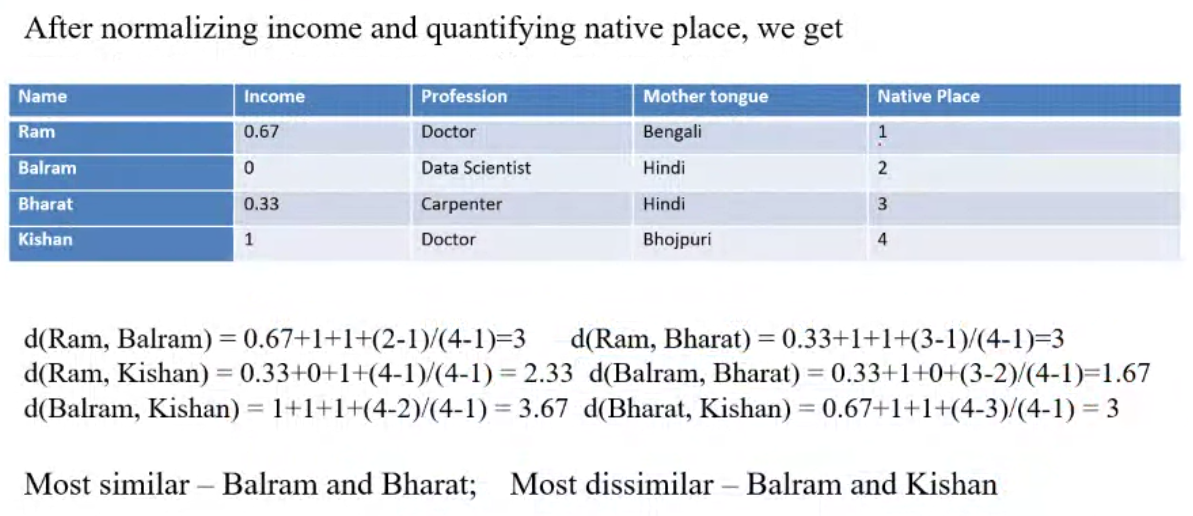
Cosine Similarity#

K Means Algorithm#
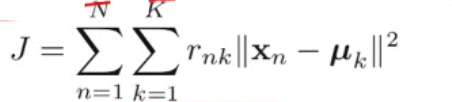
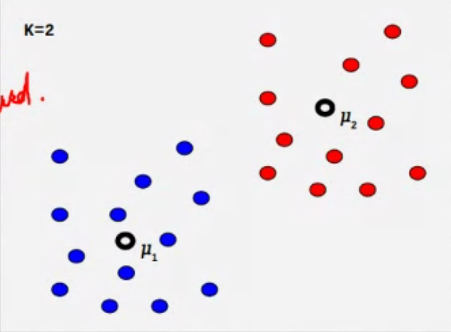

Clustering tendencies#
- All clustering algos find some clusters, even if the data does not have natural clusters or not
- Alternativuelt we can directly check the data for clustering tendency. A common approach is to use statistical tests for spatial randomness among data points
We use Hopkins statistics helps in checking if the data is nearly uniformly distributed and applying the algo is not worth it.
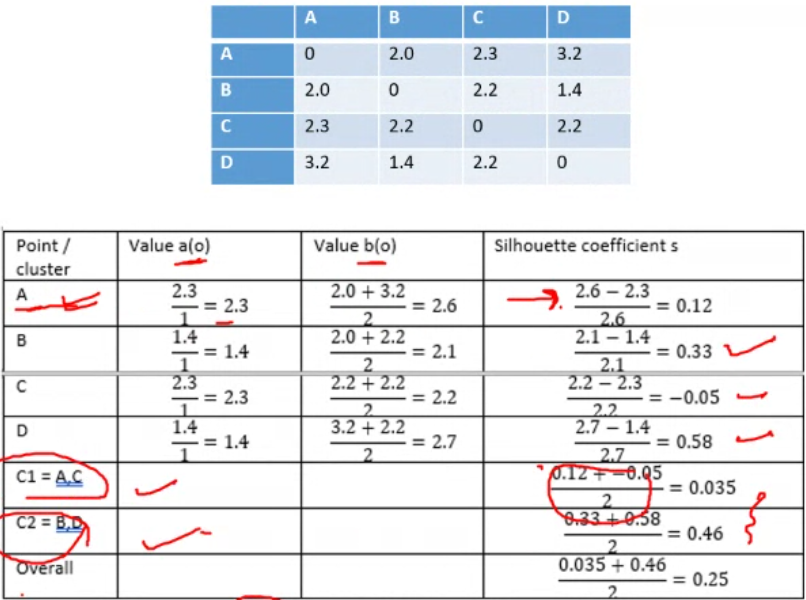
Silhouette score#
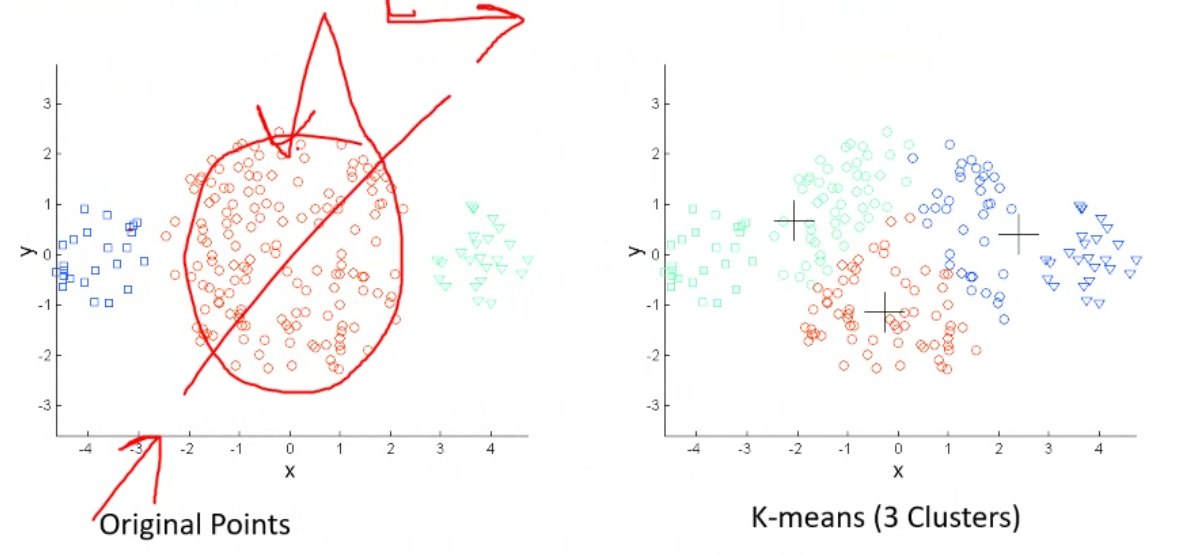
Limitations#
- When clusters are of different sizes there is a chance that a big cluster can be split because K means assumes that the clusters are of the same size
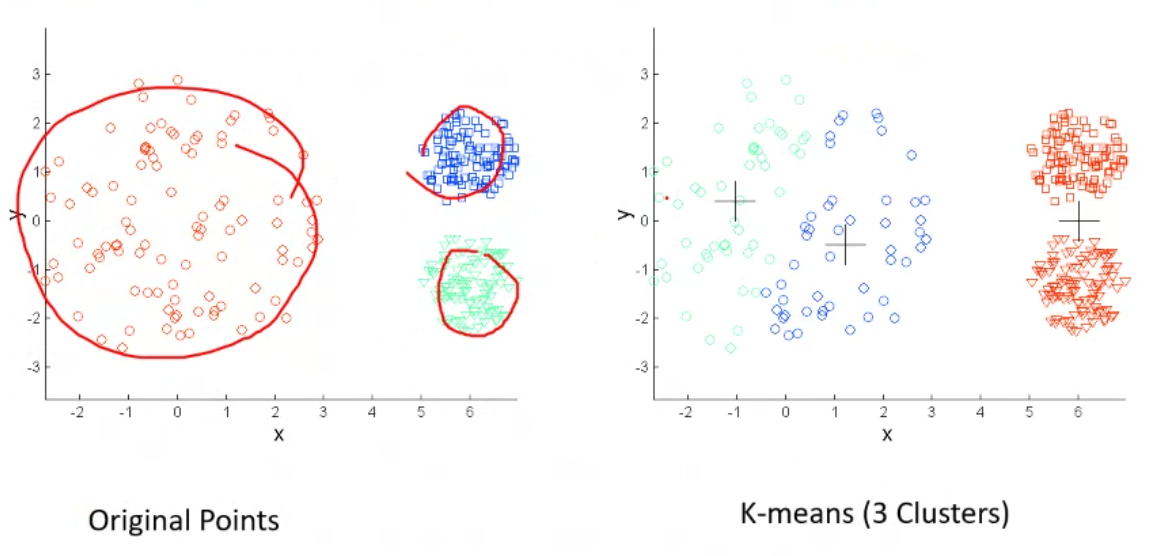
- Different density within clusters can also cause the above mentioned issue
Gaussian Mixture Models#
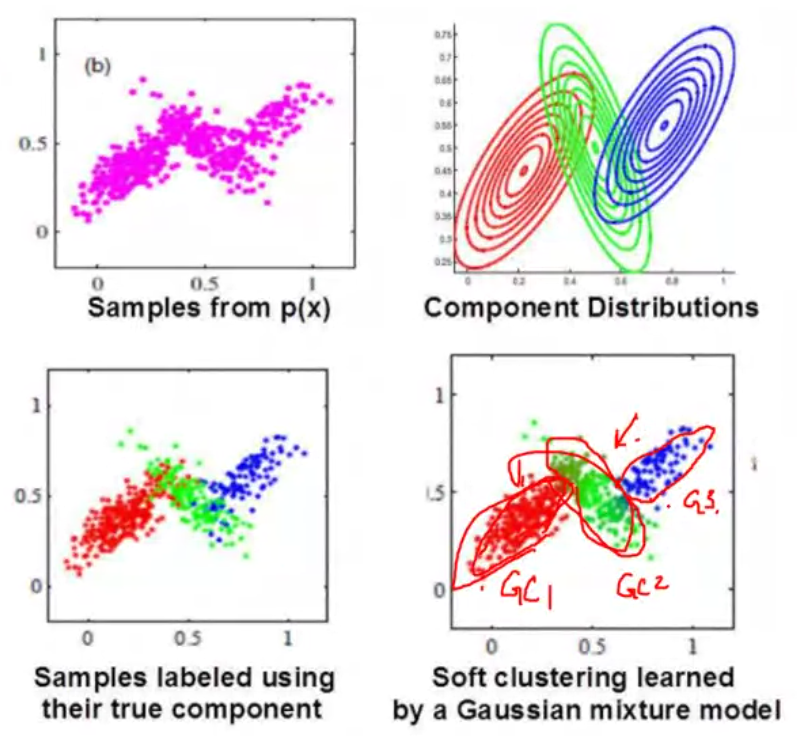
We use multiple simple distributions and
Tags: !AMLIndex